
Before talking about the importance of the Data versioning using the DVC, let’s first talk about the day-to-day challenges for Data scientists
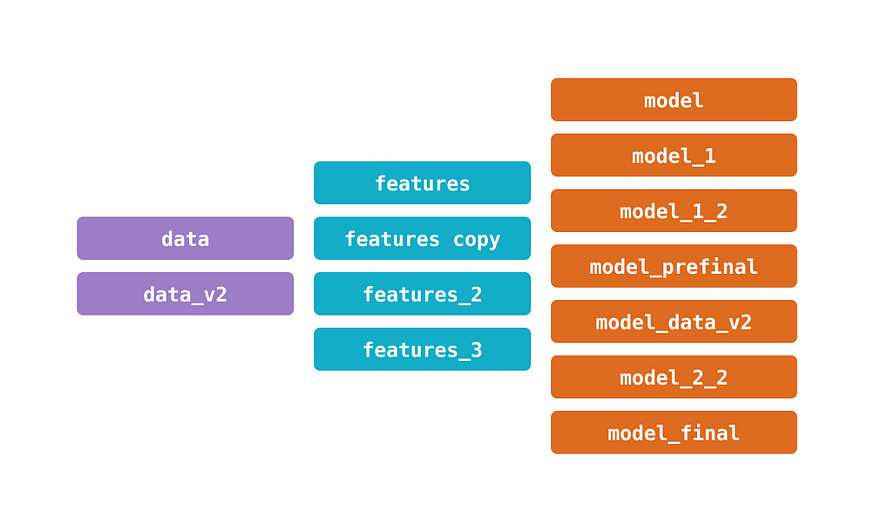
Data versioning can be very useful for data reproducibility, trustworthiness, compilation, and auditing. Data versions uniquely identify revisions of a dataset, and the uniqueness helps consumers of such a dataset know whether and how the dataset has changed over a given period. They are able to identify specifically which version of the dataset is being used.
DATA VERSIONING USE CASES
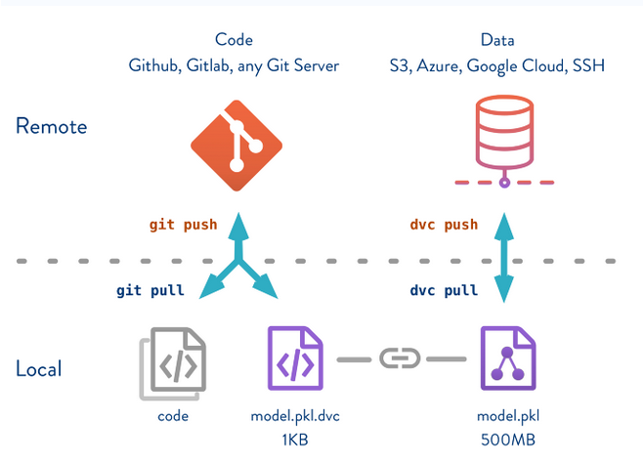
WHY DVC ?

DVC BEST PRACTICES
Common situations with DVC
Let’s say that 2 people P1 and P2 are working together on a machine learning project with an image data set. P1 works on branch B1 and P2 works on branch B2. The initial data set data/ (tracked by data.DVC) they are working on is the D1 version:
CONCLUSION
In this post, we learned about the importance of Data versioning using the DVC and how it can help data scientists. There are other paid tools in the market for data versioning, there are a lot of features that can be explored.
Thank you so much for spending your precious time reading this article. If you have any questions or comments, leave them below. I will try to answer them as good as I can.
See you in the next post!